
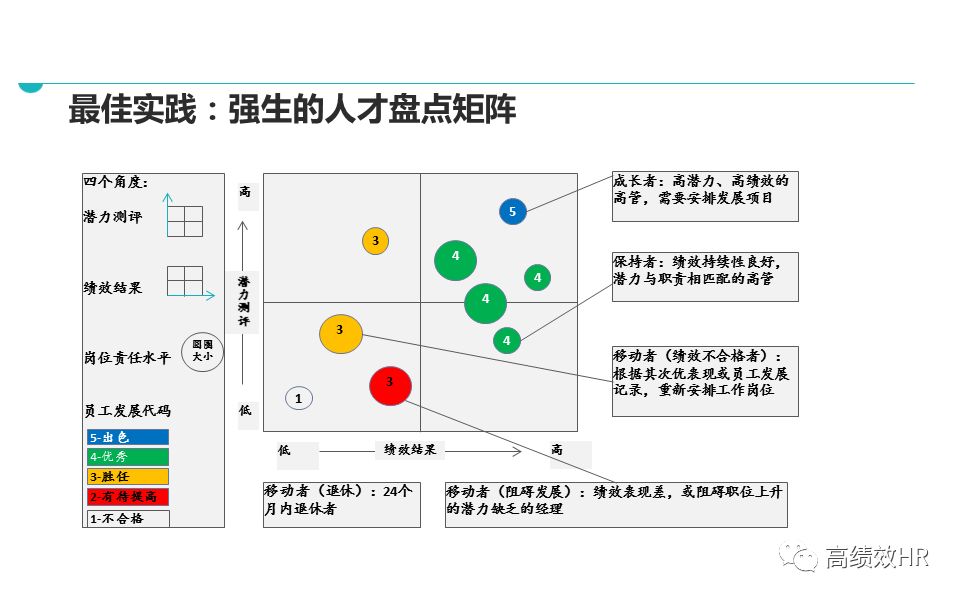
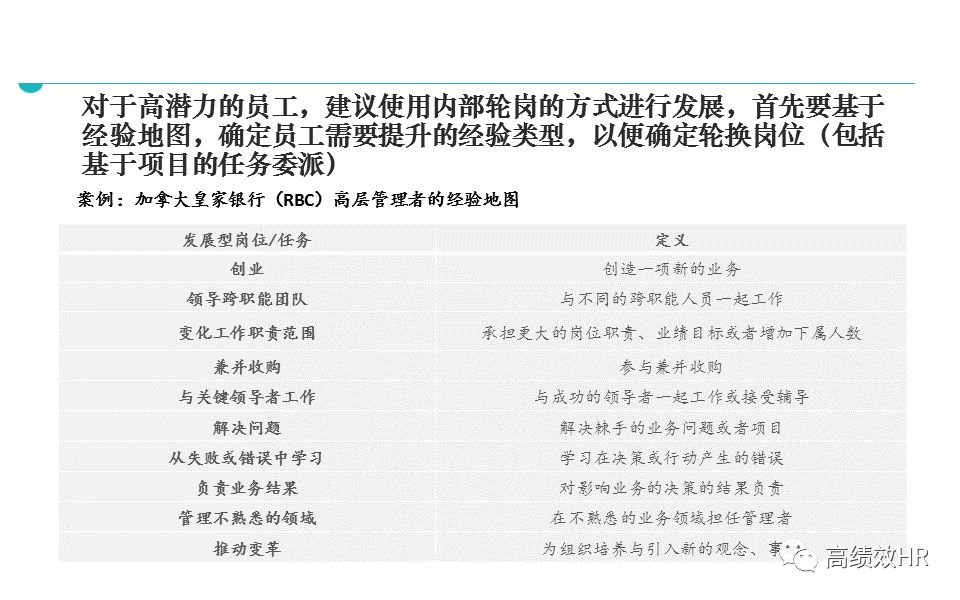
一、引言
在数据分析的领域中,预测模型的构建与验证是一项至关重要的工作,它既能够帮助我们理解数据背后的规律,还能够为未来的决策提供有力的支持,本文将详细介绍如何使用Python及其相关库来构建一个基本的预测模型,并通过一系列步骤进行验证和优化。
二、数据准备
我们需要准备用于构建预测模型的数据,这些数据可以来自各种来源,如公开数据集、企业内部数据或通过爬虫技术获取的数据,在本例中,我们将使用一个公开的房价预测数据集作为示例。
1、数据收集:从公开数据源下载数据集,并将其存储在本地文件中。
2、数据预处理:对数据进行清洗、去重、缺失值处理等操作,以确保数据的质量和一致性。
3、特征选择:根据业务需求和数据特性,选择合适的特征作为模型的输入。
4、数据分割:将数据集分为训练集和测试集,以便在训练过程中评估模型的性能。
三、构建预测模型
使用Python中的机器学习库(如scikit-learn)来构建预测模型,在本例中,我们将构建一个线性回归模型作为基线模型。
1、导入必要的库:
import numpy as np import pandas as pd from sklearn.model_selection import train_test_split from sklearn.linear_model import LinearRegression from sklearn.metrics import mean_squared_error, r2_score
2、加载数据:
# 假设数据已经预处理并存储在CSV文件中
data = pd.read_csv('housing_data.csv')3、特征选择与数据分割:
# 选择特征和目标变量 X = data[['feature1', 'feature2', 'feature3']] # 示例特征 y = data['price'] # 目标变量 # 分割数据为训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
4、构建线性回归模型:
model = LinearRegression() model.fit(X_train, y_train)
5、模型预测与评估:
# 在测试集上进行预测
y_pred = model.predict(X_test)
# 评估模型性能
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f'Mean Squared Error: {mse}')
print(f'R^2 Score: {r2}')四、模型优化与验证
为了提高模型的性能和泛化能力,我们需要对模型进行优化和验证,这包括调整模型参数、使用交叉验证等技术。
1、调整模型参数:
通过网格搜索(GridSearchCV)或随机搜索(RandomizedSearchCV)等方法,可以找到最佳的模型参数组合。
from sklearn.model_selection import GridSearchCV
# 定义参数网格
param_grid = {'alpha': [0.1, 1, 10]}
# 创建网格搜索对象
grid_search = GridSearchCV(estimator=model, param_grid=param_grid, cv=5)
# 在训练集上进行网格搜索
grid_search.fit(X_train, y_train)
# 输出最佳参数和最佳得分
print(f'Best parameters: {grid_search.best_params_}')
print(f'Best cross-validated score: {grid_search.best_score_}')2、交叉验证:
使用交叉验证(如K折交叉验证)可以更准确地评估模型的性能。
from sklearn.model_selection import cross_val_score
# 在训练集上进行K折交叉验证
scores = cross_val_score(model, X_train, y_train, cv=5)
# 输出交叉验证得分的平均值和标准差
print(f'Cross-validated scores: {scores}')
print(f'Mean: {np.mean(scores)}, Standard Deviation: {np.std(scores)}')3、模型验证:
使用测试集对最终选定的模型进行验证,以确保其在实际数据上的表现。
# 在测试集上进行预测
y_pred_final = grid_search.best_estimator_.predict(X_test)
# 评估模型性能
mse_final = mean_squared_error(y_test, y_pred_final)
r2_final = r2_score(y_test, y_pred_final)
print(f'Final Mean Squared Error: {mse_final}')
print(f'Final R^2 Score: {r2_final}')五、结论与展望
通过上述步骤,我们成功构建了一个基本的预测模型,并通过一系列优化和验证步骤提高了模型的性能和泛化能力,数据分析是一个不断迭代和优化的过程,在未来的工作中,我们可以尝试以下方向来进一步提升模型的性能:
1、尝试更复杂的模型:如决策树、随机森林、梯度提升机等。
2、特征工程:通过特征选择、特征提取和特征构造等方法,进一步提升模型的性能。
3、超参数优化:使用更先进的优化算法(如贝叶斯优化)来寻找最佳的超参数组合。
4、集成学习:通过结合多个模型的预测结果来提高整体性能。
转载请注明来自铭坤戈,本文标题:《2024年澳门六和彩资料免费|精选解释解析落实》





 京公网安备11000000000001号
京公网安备11000000000001号 京ICP备11000001号
京ICP备11000001号